Let the model talk
Recent advances in machine learning, especially in deep neural networks (DNNs), as well as the availability of training data, have persuaded individuals and companies to apply them to various real-world applications, including movie recommendation, speech recognition, and machine translation, as few legitimate examples. However, similar to any other tools or technologies, machine learning is a double-edged sword as it has been abused for illegal purposes too. One example of such illegitimate use case is creating fake videos by leveraging DNNs, introduced to the public as deep fake.
Regardless of the application context, complex machine learning models such as variants of DNNs are not transparent to data scientists and users both in terms of architecture and the decisions they make. One has commonly limited to zero knowledge about why a particular model has mapped an observed instance to a particular class. This can lead to a lack of trust where machine learning is applied. Therefore, interpretability (also, known as explainability) of complex machine learning models is of the utmost importance, specifically in security-sensitive areas. For this reason, machine learning interpretability has emerged as a new paradigm in machine learning.
Throughout this blog post, I will first present a few applications of interpretability in machine learning. Then, I will review different methods proposed for machine learning interpretation.
Applications
Interpretations can help in understanding the most relevant features and true evidence in model decisions, a process known as model validation. They can also help in examining if a model has instead employed biases that do exist in the training data for any specific decision. Examples of such biases are age, gender, geographical locations, and minority groups to name a few.
Machine learning models do not work as expected in all circumstances. Thus, interpretations can help in analyzing and understanding the root cause of misbehavior in different models, also known as model debugging. Several recent works have shown that DNNs can be guided at a low cost (e.g., via adversarial inputs) to make imprecise decisions with high confidence. However, these crafted adversarial inputs are usually easy to be told apart from regular inputs by humans.
Last but not least, interpretations enable humans to obtain detailed insight from machine learning models by understanding their decision-making processes and their architectures. Experts can leverage such information to provide realistic feedback and to acquire new knowledge.
Machine Learning Interpretation
Machine learning models are interpreted in two general ways, depending on the time when interpretation is performed, including the intrinsic interpretation and post-hoc interpretation (Fig. 1). Approaches in the first category incorporate interpretation directly into models' structures by creating self-explanatory models, whereas methods in the second category provide interpretations for an already built (and/or trained) model commonly by developing a second model. Intrinsic and post-hoc interpretations can be applied at different granularity levels. They can be used to provide explanations at a per model (global interpretability) or per decision scale (local interpretability). In addition, interpretation approaches can be designed by considering the structure and hyper-parameters of a target model (model-specific interpretability), or, they can be designed without considering the model's constraints (model-agnostic interpretability).
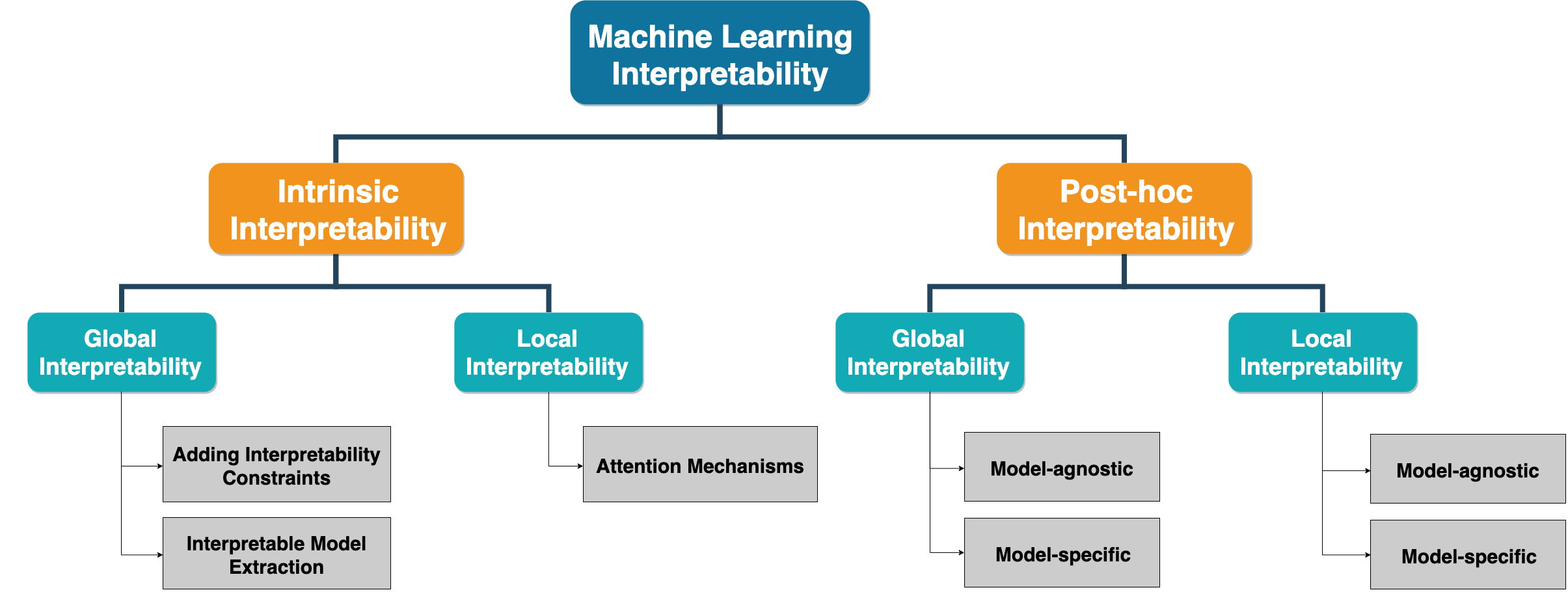
Intrinsic Interpretability
As presented earlier, intrinsic interpretability is achieved by designing self-explanatory models from the scratch. An intrinsic interpretable model can provide explanations for the model and its hyper-parameters which is commonly known as global (or per model) interpretability. Or, it can provide explanations for the decisions it makes for each instance (i.e., the label a particular classifier assigns to an instance), referred to as local (or per prediction) interpretability.
A very straightforward global approach is to incorporate constraints into models at the training stage. An alternative way is to extract an easily interpretable model from a complex one through a process known as mimic learning. On the other side, locally interpretable models are achieved by designing model architectures that could explain why a specific decision is made. As an example, the attention mechanism is an approach that is widely utilized to explain predictions for sequential models such as Recurrent Neural Networks (RNNs).
Post-hoc Interpretability
When a machine learning model is trained, it retains the learned knowledge into the model structure and parameters. Thus, post-hoc interpretability aims at providing a global understanding of the acquired knowledge by any pre-trained models. Another goal of post-hoc interpretability is to present the parameters or the learned representations to humans intuitively. Similar to intrinsic interpretability, post-hoc interpretability provides explanations at two different scales, including global (per model) and local (per prediction).
A popular post-doc method from the global category is feature importance. Most machine learning algorithms rely on feature engineering, which converts raw data into features that better represent the predictive task. The features are commonly interpretable and the role of a machine learning algorithm is to map the representation to output. For such algorithms, the feature importance can provide the data scientist with the statistical contribution of each feature to the underlying model when making decisions. Feature importance is known to be a model-agnostic post-hoc method and can be applied to various machine learning models. Permutation feature importance is a specific variant of this method that determines the importance of each feature to the overall performance of a model by calculating how the model prediction accuracy deviates after permuting the values of that feature. There also exist post-hoc methods specifically designed for different models that are referred to as model-specific. These methods usually derive explanations by examining the internal model structures and parameters. In what follows, some of these methods are discussed briefly.
In Generalized Linear Models (GLMs) such as linear regression and logistic regression, the weights of a model can reflect the feature importance. So, analysts can understand how the model works by checking and visualizing its weights. However, when features are not properly normalized and have different distributions, weights cannot be a reliable indicator of feature importance. Furthermore, the interpretability will decrease as the data dimension becomes too large, which may be beyond the comprehension ability of humans.
Unlike GLMs, tree-based models such as random forests and XGBoost are typically inscrutable to humans. However, there are a few ways that can be leveraged to measure the contribution of each feature in these complex models. The first approach is to calculate the accuracy gain when a specific feature is used in tree branches. The rationale is that without adding a new split to a branch for a feature, there may be some misclassified elements, while after adding the new branch, there are two branches and each one is more accurate. The second approach is to measure the feature coverage by calculating the relative quantity of observations related to a specific feature. The last but not least method is to count the number of times a feature is used to split the data.
Some machine learning algorithms are capable of learning representations from raw data in addition to discovering the mapping from representations to output. Deep Neural Networks (DNNs) can efficiently achieve this goal. However, the learned representations are not human interpretable. Therefore, the explanation for DNNs mainly focuses on understanding the representations captured by the neurons at intermediate neural layers (or hidden layers). For instance, there has been a growing interest to understand the inscrutable representations at different layers of Convolutional Neural Networks (CNNs) that are vastly being applied to image classification tasks. In a typical scenario, an image is optimized to maximally activate a specific neuron, starting from random initialization. Then, the derivatives of the neuron’s activation value with respect to the image are utilized to tweak the image in a repetitive optimization process. Eventually, the visualization of the generated image could tell what the neuron is looking for in its receptive field. Recurrent Neural Networks (RNNs) have also attracted increasing interest due to their power in language modeling. To find explanations for the decisions made by such complex models, some methods have been proposed that examine the representations of the last hidden layer of RNNs and study the function of different units at that layer by analyzing the real input tokens that maximally activate a unit.
Post-hoc interpretability not only tries to explain the model itself but also every single prediction it makes. Local explanations target to identify the contribution of each feature in the input toward a specific model prediction, and they are divided into model-agnostic and model-specific approaches.
Model-agnostic methods allow explaining predictions of arbitrary machine learning models independent of the implementation. So, these methods treat the model as a black box, where explanations could be provided even without any knowledge about the internal model parameters. For example, permutation-based explanation tries to identify the contribution of each feature by measuring how the prediction score changes when a specific feature is altered, regardless of the model structure and parameters. On the other hand, an example of a local model-specific method is backpropagation that is being used in DNNs. Backpropagation methods calculate the gradient, or its variants, of a particular output with respect to the input and forward it from the output layer back to the input layer to derive the contribution of features. The idea is that a larger gradient magnitude represents a more substantial relevance of a feature to a prediction.
Conclusion
Interpretable machine learning is an important field of research, especially with the emergence and application of DNNs to various sensitive tasks. Most of the proposed explanation methods do not take end users' demands into account. For example, existing local explanations are usually given in the format of feature importance vectors, which are considered low-level explanations. Therefore, more human-friendly global and local explanations are needed in applications where end users are not necessarily machine learning researchers. A good and efficient model explanation not only helps in knowledge discovery but also facilitates model validation and debugging.