Android app triage and malware detection
Android is by far the leading operating system in smartphones. As of March 2019, 51% of US smartphone subscribers were using a Google Android device. This percentage is much higher in an international scale. Also, there are currently more than 2 million Android applications on the official Google Market, known as Google Play. As most of the functionalities of smartphones are provided to users via applications, this huge market with billions of users is tempting for attackers to develop and distribute their malicious applications (or malware).
Mobile malware has raised explosively since 2009. Symantec reported an increase of 54% in the new mobile malware variants in 2017 as compared to the previous year. This rise has happened for Android malware as well since only 20% of devices are running the newest major version of Android OS based on Symantec report in 2018. Thus, detecting malicious and potentially risky applications in the Android platform is of the utmost importance.
Four main tasks are commonly performed in a malware analysis pipeline, including reverse engineering, static analysis, dynamic analysis and triage analysis. Reverse engineering is the process of using tools (e.g., disassemblers and decompilers) and techniques to understand how a malware works and what it does. Static analysis is the process of using tools (most often reverse engineering tools) to obtain as much information as possible from the app before execution, while dynamic analysis tries to achieve the same goal by monitoring the app’s runtime behavior (e.g., processes, memory read/writes or network traffic) through running it in a simulated environment (or a sandbox). While static and dynamic analyses are somehow effective, they need a significant amount of resources. This is exactly when triage analysis comes into play. The main purpose of this step is to narrow down the process of malware analysis by using fast techniques so that we can spend resources on more sophisticated malware and can thus save time and computational resources. During this blog post, I will first discuss various anti-analysis techniques used by Android malware to evade both Android app triage and Android malware detection systems. Then, I will briefly review different automated systems proposed for Android application triage and Android malware detection.
Iconography
Before starting the review, I would like to present the icons and their meanings which are used throughout this blog post (Fig. 1). A smiling cat icon stands for any Android app triage system with loose security regulations, whereas an angry cat icon shows any malware detection system with strict security policies. On the opposite side, a mouse icon demonstrates any technique which can be leveraged to bypass malware detection systems.

Common Anti-Analysis Techniques in Android Malware
A wide range of methods have been used by Android malware to evade both app triage and malware detection systems in recent years. Data manipulation (data poisoning), obfuscation, dynamic code loading, using malicious native payloads, packing, repackaging and piggybacking are few techniques that can affect the performance of systems that solely rely on features extracted via static analysis of applications. On the other hand, advanced emulation detection techniques are used to degrade the performance of systems which do rely on features extracted from the app's runtime behavior.
Data manipulation is the process of changing the app's bytecode and/or its manifest file (Manifest.xml) by adding or obscuring some features that are used either to create signatures or to train ML-based systems. In the Android security ecosystem, permissions, app's components, intents, API methods and control flow graphs of apps are some features that can be modified with trivial effort.
Obfuscation techniques modify an app's source (or machine) code in order to make it more difficult to analyze. They are typically applied to protect intellectual property in benign apps, or to hinder the process of extracting actionable information in the case of malware. Obfuscation has been vastly applied to Android malware in recent years. In particular, identifier renaming, string encryption and control flow obfuscation are frequently applied to Android malware since they are either available in free obfuscators or in the trial versions of commercial obfuscators. Also, they create a satisfactory level of confusion in the app’s source code. Furthermore, reflection is another obfuscation method vastly applied to Android malware to evade detection systems.
Android malware may hide its malicious functionality in a separate Dalvik Executable (.dex) file and load it at runtime. In the extreme scenario, this dex file may be encrypted to be decrypted dynamically during the app's execution. For instance, variants of Fobus family decrypt their malicious payload at runtime. Android malware uses other ways to load this payload as well. Variants of RuMMS family load their payloads from the assets or res directories which normally contain the app's resources, including its fonts and images. Or, malware specimens in SlemBunk family download their payloads from a remote server. Also, few malware samples in TGLoader family hide their malicious functionality in native payloads to add an extra level of complexity ahead of systems that mainly rely on the app's bytecode to distinguish malware from benign applications.
Packing techniques transform the original app into an encrypted form using advanced encryption methods. Decryption code is commonly embedded into the same dex file to be exercised at runtime. The ratio of malware samples being packed has increased significantly in recent years as commercial packers gain more and more popularity; specifically, those from Chinese companies including Baidu, Bangcle and ijiami. Compared to packing which tries to obscure the malice, repackaging techniques inject malicious code into legitimate and most often popular apps. As an example, Triout, a recently detected Android malware with spyware capabilities, hides behind a popular VPN app, called Psiphon. Finally, in contrast with common repackaging, where the code of original apps may not be modified, piggybacking grafts additional code to inject an extra, often malicious, behavior to original apps. The original app in this context is known as the carrier, while the grafted payload is known as rider. A recent study shows that DexClassLoader, a class loader which is provided by the Android OS to load classes from .jar and .apk files, is used extensively by malware writers to load malicious riders dynamically.
While the majority of Android malware are hardened against static analysis, several specimens are also equipped with emulation detection mechanisms to evade dynamic analysis. For instance, variants of Pornclk family check if there are any files related to the presence of an emulator, including the presence of specific configuration files or other environmental features that can be an indicator for the existence of a sandbox.
Android App Triage Systems
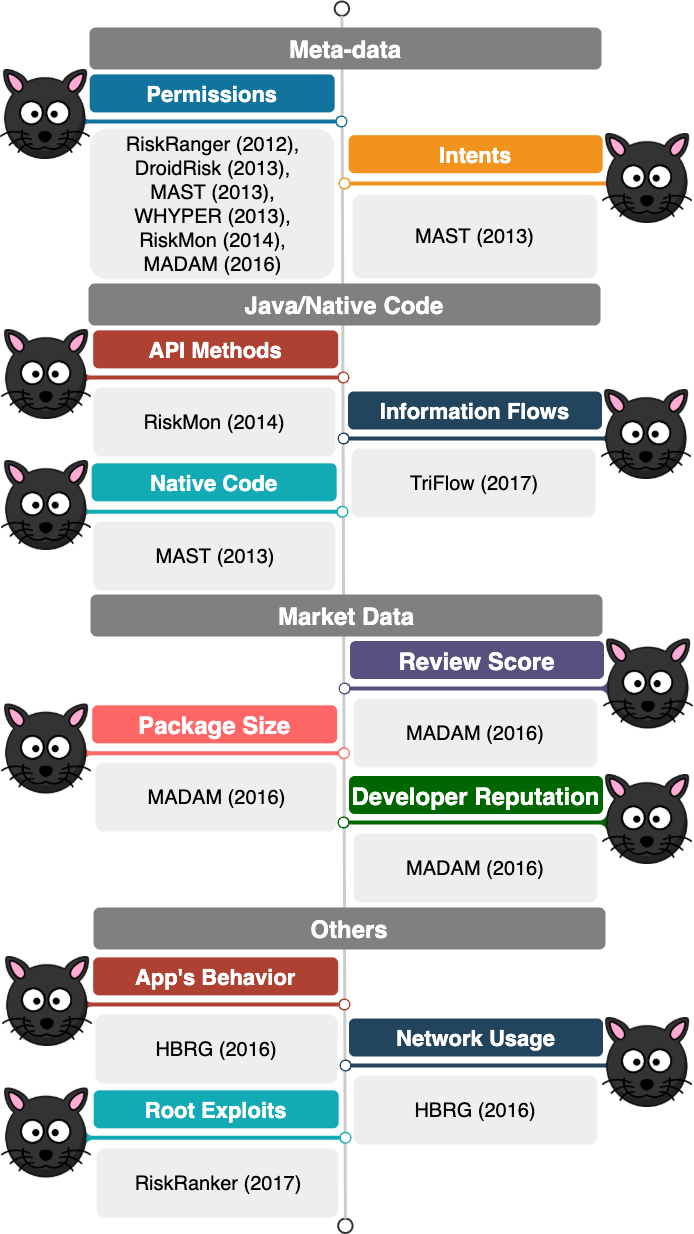
Identifying potentially dangerous and risky applications is an important step in Android malware analysis as it helps to allocate resources intelligently and guarantee that the analysis effort is devoted to those samples that potentially have more security interest. Application triage is the process of using fast tools or techniques to narrow down the malware analysis and to save time and computational resources. Android app triage systems have leveraged different features to find risky applications as shown in Fig. 2. Static features used by such systems are collected from app's meta-data, app's market data or its source code, and dynamic features are related to the app's runtime behavior.
The first group of features leveraged for Android apps triage is collected from the app's meta-data. Permissions and intents are the most common features used by previous systems. Permissions have been used in several triage systems, including RiskRanger, DroidRisk, WHYPER, RiskMon and MADAM to name a few. Permissions are mainly used to control an app's access to sensitive resources and services. However, MAST relies on intents in addition to permissions to identify risky Android applications. Intents and permissions must be declared in the app's manifest file, and, thus, can be collected easily and quickly.
While permissions are indeed access control mechanisms for sensitive resources, they do not provide fine-grained information about how and when such resources would be used. Furthermore, many apps (known as overprivileged apps) ask for a long list of permissions that they never use during their execution. Therefore, other systems have relied on features collected from app's Java and/or native code to identify risky applications. Android apps access critical resources via API methods once they are granted the corresponding permission(s). Thus, few systems like RiskMon rely on API methods for the triage task. However, API methods alone are not reliable enough to show the amount of risk posed to the user by any application. Therefore, other triage systems such as TriFlow leverage static taint analysis to follow flows of information from source methods where sensitive (device/user)'s data are collected to sink methods where such information may be leaked. Many systems solely rely on the features extracted from app's Java code. Nevertheless, studies show that malicious functionality is frequently implemented via native code. Thus, systems like MAST rely on the presence of native code in addition to permissions and intents to identify risky apps.
The third group of features used by triage systems is obtained from online markets via techniques such as crowd sourcing. Review score of an application, its developer reputation, and, sometimes, its package size can all show whether or not an application is dangerous according to a recent study. Usually, apps with a very low review score or developer reputation should be treated carefully.
All features discussed previously can be obtained through static analysis and are easy to collect. Nevertheless, apps which are hardened against static analysis techniques can easily bypass these systems. As a result, other academic systems, including HBRG and RiskRanker leverage dynamic analysis to triage Android apps. App's runtime behavior, its network usage and the pattern of system calls (e.g., for root exploits) are some features used by such systems.
Android Malware Detection Systems
Similar to their counterparts which fight against desktop malware, Android malware detection systems fall into two broad categories, including signature-based systems and Machine Learning-based (ML-based) Systems. Systems in the first category rely on unique signatures generated from specific attributes of applications (e.g., unique sequences of bytes). If an app is found to be malicious, its signature is added to a database that is used later to spot other malicious apps if and only if they share the same signature. Most of the commercial Anti-Virus (AV) products use these types of systems to detect Android malware though a number of them have recently applied more advanced mechanisms based on machine learning. Systems in the second category, ML-based malware detection systems, leverage machine learning algorithms to distinguish malware from benign applications.
Both signature-based and ML-based systems for Android malware detection have their own limitations. First, signatures used by signature-based malware detection systems have to be updated periodically and in short intervals. Otherwise, they will fail to detect malware samples whose signatures are not present in the database. Second, such systems cannot detect previously unseen malware, known as zero-day malware. Last but not least, signature-based systems are commonly unable to detect malware variants which are continuously changing their key characteristics, including oligomorphic, polymorphic and metamorphic malware. ML-based systems on the other side, need a considerable amount of computational resources; they need to be re-trained in different intervals, and they are vulnerable to adversarial attacks.
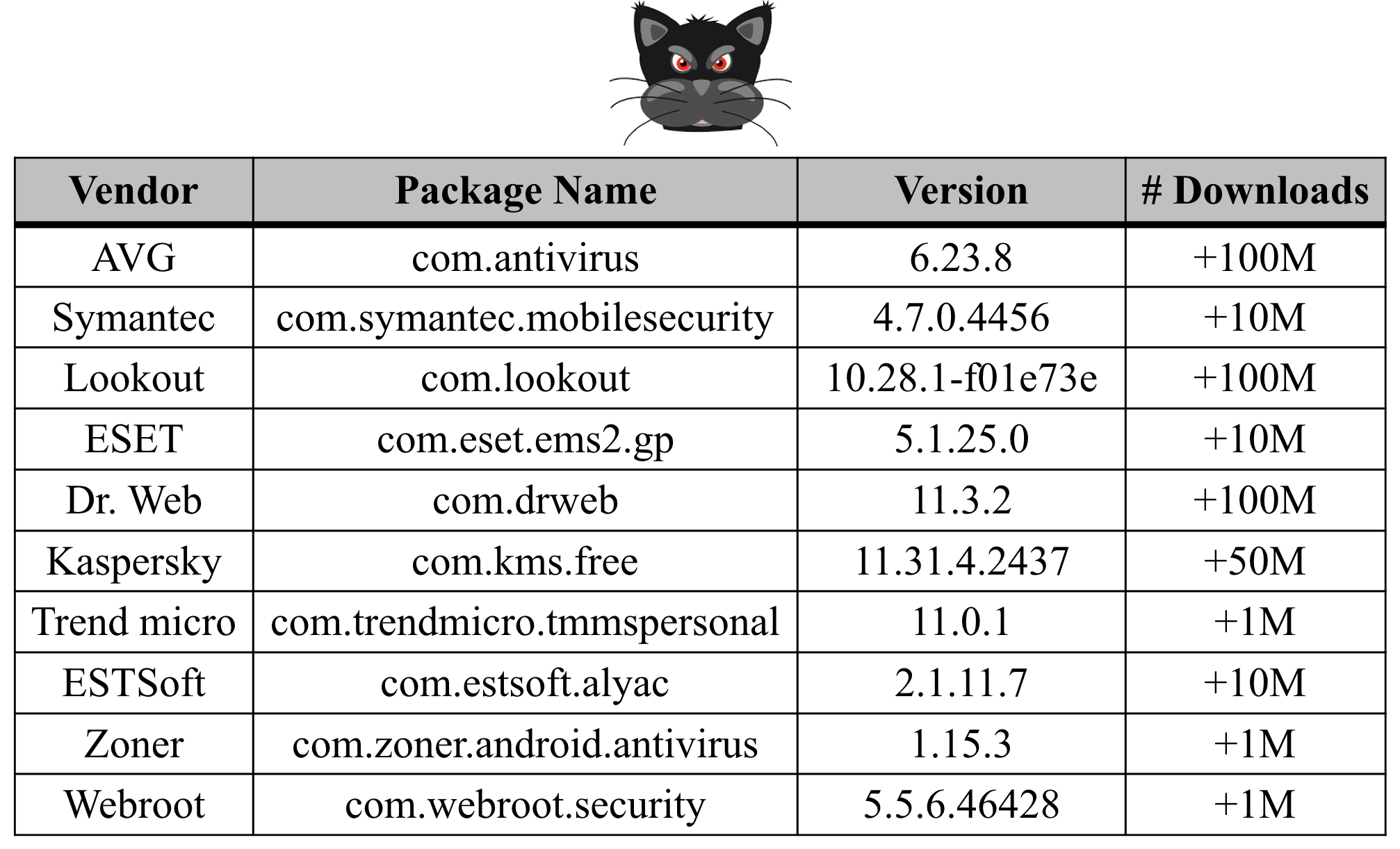
One of the most common signatures used by anti-virus products or scanners to detect known malware is the hash value of malware specimens. A database of hashes related to previously seen malware is kept by these products to compare new submitted apps against all recorded hashes. However, these hashes can be easily modified and can thus disguise the submitted app as a totally new malware specimen, which in reality, has an identical malicious functionality with an already detected application. Table 1 contains the most popular anti-virus scanners with their number of downloads as of October 2019.
MD5, SHA256 and SHA512 are some cryptographic hash functions which are used by cybersecurity researchers to find previously known malware. The principle idea behind using these hash functions is to check whether a submitted sample is new, or it has been already detected in the wild. When using traditional cryptographic hashes, a single hash is created for the entire file. Thus, a single bit change has an avalanche effect on the output hash value. However, Context Triggered Piecewise Hashes (CTPH), also known as fuzzy hashes, are calculated by using multiple traditional cryptographic hashes for multiple fixed-size segments of an input file. Therefore, if a byte of the input is changed, only one of the traditional hash values (or at most two) will be changed; the majority of the CTPH signature will remain the same. Since the majority of the signature remains the same, files with modifications can still be associated with the CTPH signatures of known files.
As discussed earlier, trivial transformations can defeat signature-based detection systems which rely on traditional algorithms to generate hashes based on whole files. Some of these transformations do not even require code-level changes or modifications to meta-data stored in the manifest file of applications. Repackaging, disassembling and reassembling, obfuscation and reflection are just few methods that can be used to evade signature-based detection systems (Fig. 3). In the repacking technique, the app package which is in the form of a compressed file (zip file) is unzipped with a regular zip utility, and, then, repacked again with tools offered in the Android SDK using a custom key. In the disassembling and reassembling technique, the compiled Dalvik bytecode (in classes.dex file) is disassembled, and, next, various items in this file are rearranged or represented in different ways. Finally, the bytecode is reassembled back again. Both of these simple methods can be applied to Android malware to evade signature-based systems with trivial effort. Different obfuscation techniques, including data encryption, identifier renaming, control flow obfuscation (e.g., inserting goto instructions, function outlining/inlining) and code reordering are more advanced methods that can be applied to malicious apps to evade such systems. Additionally, replacing API methods with reflective calls can affect the performance of these systems.

To compensate for the deficiencies of signature-based malware detection systems, specifically their inability to detect zero-day malware, ML-based detection systems are proposed. These systems can be categorized into different groups based on three important criteria: 1) How features are extracted? 2) Which ML algorithm(s) is(are) applied? and, 3) Where the ML model is kept? ML-based detection systems are divided into three groups based on the analysis technique they use to extract their features, including static, dynamic and hybrid analyses. They can rely on one single learning algorithm or a combination of two or more algorithms, known as ensemble learning. Furthermore, the trained model can be kept in different places, including within the device itself, out of the device (e.g., on a remote server), or on the cloud.
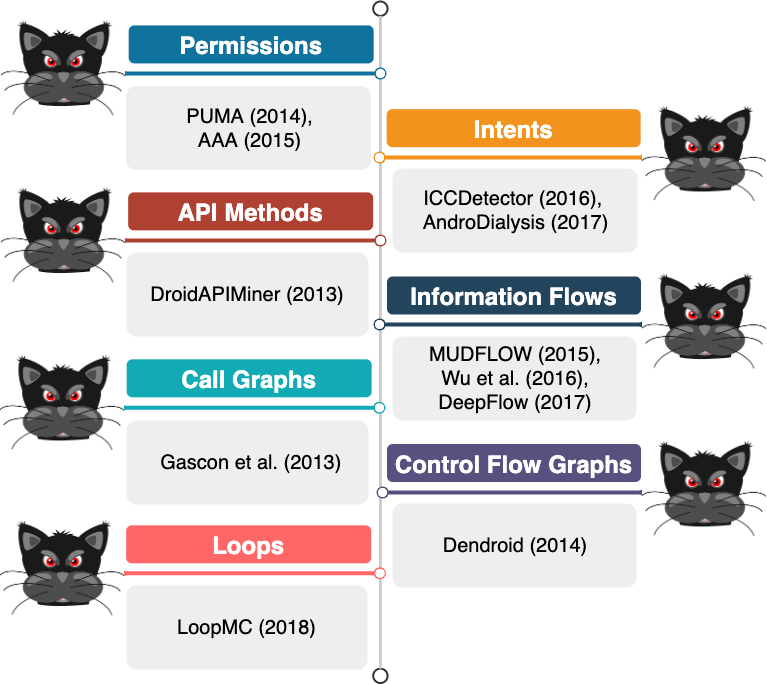
ML-based Android malware detection systems that leverage static analysis to extract their features have relied on different app features as shown in Fig. 4. Permissions (e.g., PUMA and AAA), intents (e.g., ICCDetector and AndroDialysis), API methods (e.g., DroidAPIMiner), information flows extracted via static taint analysis (e.g., MUDFLOW and DeepFlow), call graphs (e.g., Gascon et al.), control flow graphs (e.g., Dendroid), and, most recently, loops (e.g., LoopMC) are the most important features used in academic malware detection systems. While such features are easy to collect in most cases, they can be manipulated in various ways to degrade the performance of systems that are solely trained based on static features (Fig. 5).
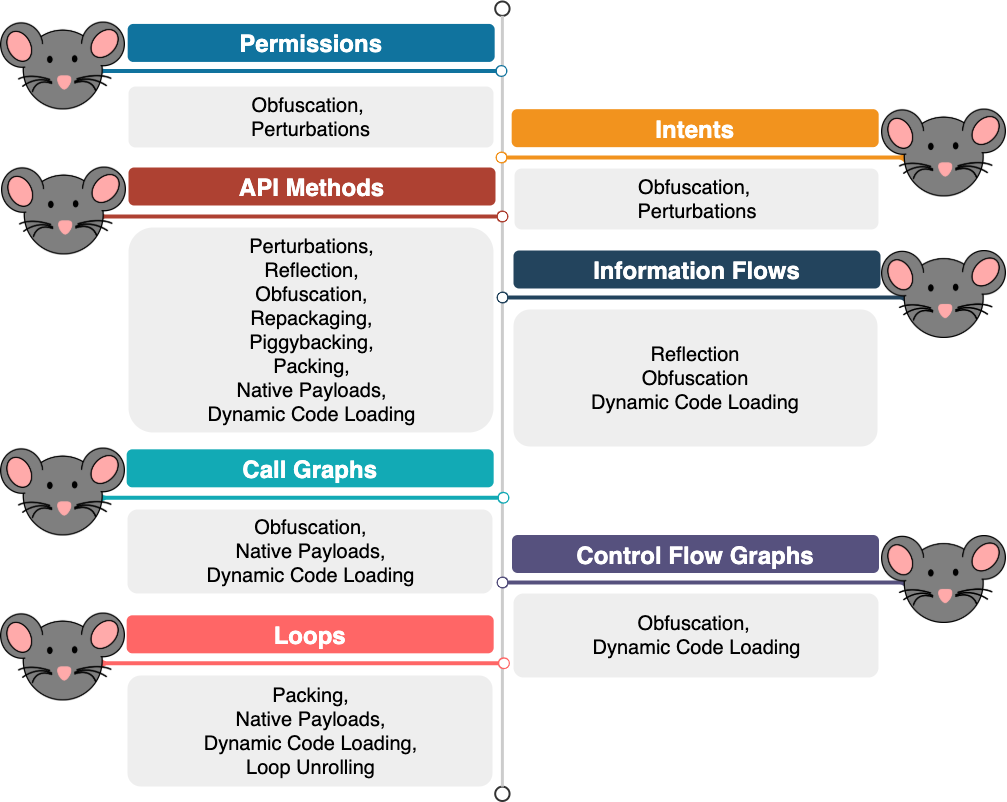
Permissions and intents are both declared in the manifest file of Android apps. An adversary can use any of open-source tools to unzip and decode the manifest file, and, finally, to manipulate (or perturb) its features with almost no effort. As an example, adding several permissions or intents to malware specimens which were commonly observed in benign samples during the training phase, can easily affect the performance of ML-based systems that rely on these features and can produce false negatives. Also, obfuscation can hide or obscure dangerous permissions in malicious applications and will make these systems to misidentify a malware sample as a benign application.
API methods are also available to adversaries with minimum effort. They can be either extracted from the classes.dex file directly using a dalvik parser, or, alternatively, from the disassembled bytecode. Although API methods can somehow reflect the behavior of Android applications, they can be manipulated by adversaries using a wide range of techniques to disguise malware samples as benign apps. The simplest technique is to add as many benign API methods as possible to a malware specimen to make it look like legitimate or benign apps. In addition, repackaging and piggybacking can both generate false negatives in the ML-based system as they inject malicious functionality containing dangerous API methods into legitimate apps with API methods mainly observed in benign apps. On the other hand, few methods such as reflection, obfuscation and packing can all help malware writers to obscure or hide sensitive API methods. Finally, malicious functionality (with API methods) can be included solely in the native code, and, in the most extreme scenario, it can be called during app's execution.
Due to the accessibility of permissions, intents and API methods, these features are much prone to manipulation. Thus, researchers have tried to come up with more accurate, fine-grained and complex features like information flows. Information flows are extracted through a process known as taint analysis where sensitive data, from specific sources, is tainted and tracked until it reaches specific sinks through the application's data flow and sometimes control flow graphs. Taint analysis is performed either in a static or dynamic way. The former technique is done before app's execution and outside the operating environment, while the latter is done at runtime and while executing the app in an emulated environment. Few techniques can obviously affect the performance of static taint analysis, including reflection, obfuscation and dynamic code loading. Replacing API methods, as common source and sink points in taint analysis, with reflective calls or control flow obfuscation can hide some control dependencies and explicit data assignments and will thus lead to under-tainted results. In addition, dynamic code loading and execution can help the malware to evade static taint analysis.
Recent studies show that although information flows provide a relatively accurate picture of an app's behavior, extracting them is computationally expensive. Also, the vast majority of newly discovered malware samples are indeed variations of existing malware. Therefore, call graphs are proposed as a high-level property of code which offer a suitably robust representation to account for these variations as compared to other static features. Nevertheless, other studies show that degrading the performance of systems used for extracting call graphs is not a difficult task. First, different obfuscation methods can be used to evade ML-based systems that rely on call graphs. As the first example, unreachable calls can be injected to the app's code, and, as the second example, function inlining can be used to hide the graph structure. Second, malicious functionality can be delivered via native code though some tools used for call graph extraction may analyze native code as well. Thus, a third technique to thwart static analysis is to load and execute the malicious function during the app's execution.
An alternative graph-based feature used by ML-based systems to detect and classify Android malware samples is control flow graph. Similar to other ML-based systems based on features obtained via static analysis, systems based on control flow graph are error-prone in the presence of obfuscation. Thus, an adversary can evade such detection systems by adding goto instructions or inserting junk code as two simple examples. Moreover, malware can port its malicious functionality to the native code and prevent all tools to extract the malicious control flow graphs.
A recent study makes use of more fine-grained features in the control flow graphs. The ML-based system proposed in this work relies on loops, i.e., any cycle in the control flow graph, to detect Android malware. The basic idea behind using loops is that they encode enough information required for malware detection, and they are difficult to remove or obfuscate. However, this system is also vulnerable to several types of attacks. First, packing and bytecode encryption can both help the malware to evade this system. Second, malicious functionality can be included into the native code in order to be exercised at runtime via dynamic code loading. Last but not least, a simple malware without any loops (or no-loops malware) can simply evade this detection system.
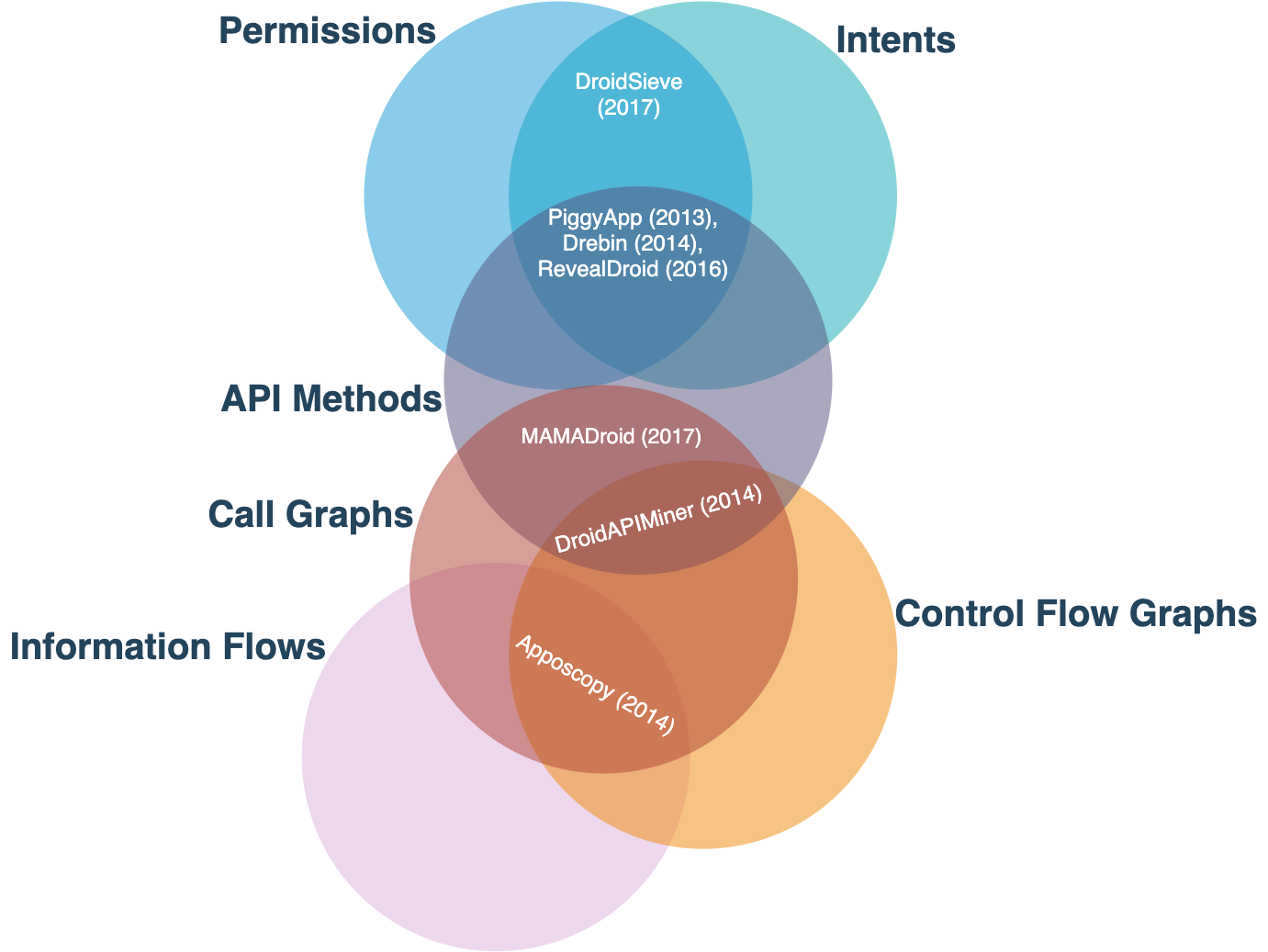
To improve the performance and robustness of ML-based systems that only rely on one single feature obtained through static analysis, few academic works have proposed systems that are trained with more than one feature as shown in Fig. 6. DroidSieve relies on both permissions and intents, while MAMADroid leverages sequences of API methods extracted from apps' call graphs. Additionally, Apposcopy is an ML-based system which is trained on features extracted from information flows and control flow graphs. Other academic systems, including PiggyApp, Drebin, RevealDroid and DroidAPIminer train their models based on more than two features. The first three systems make use of permissions, intents and API methods, whereas DroidAPIMiner relies on API methods extracted from call graphs as well as control flow graphs to train the models. While all these systems are more robust against data manipulation as more static features are involved in the training process, they are still vulnerable to more advanced attacks.
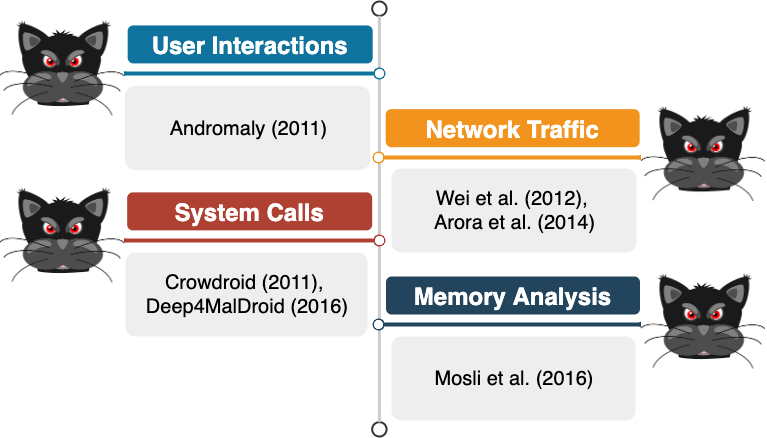
Other works have generally questioned the efficiency of ML-based systems which are trained using features extracted by means of static analysis. Therefore, they have proposed systems that are trained only with features extracted via dynamic analysis (Fig. 7). Such features are commonly obtained by running the app in an emulated environment (or a sandbox). User interactions (e.g., Andromaly), network traffic (e.g., Wei et al. and Arora et al.), system calls (e.g., Crowdroid and Deep4MalDroid) and memory read/write operations (e.g., Mosli et al.) are few examples which are usually monitored in the considered sandbox and are used to train the models.
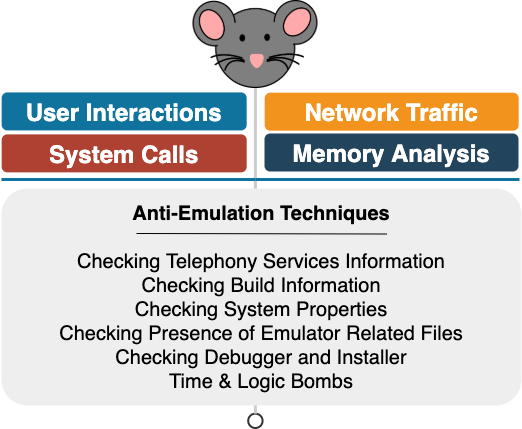
Even though dynamic analysis does not suffer from popular limitations of static analysis, several malware samples do exist in the wild capable of identifying whether or not they are running in an emulated environment. If they find a sandbox, they temporarily halt their malicious activities. Hence, ML-based systems which are solely trained with features extracted via dynamic analysis will be evaded fairly easily by such malware specimens. A wide range of features are checked by advanced Android malware to detect emulated environments (Fig. 8), including telephony services information (e.g., variants of RuSMS family), build information, system properties, presence of emulator related files (e.g., variants of Pornclk family) and the presence of debugger and installer (e.g., variants of Skinner adware). Other malware variants wait for a certain amount of time, or, alternatively, until specific criteria are met before starting their activities to bypass emulated environments. These types of malware are commonly known as time and logic bombs.
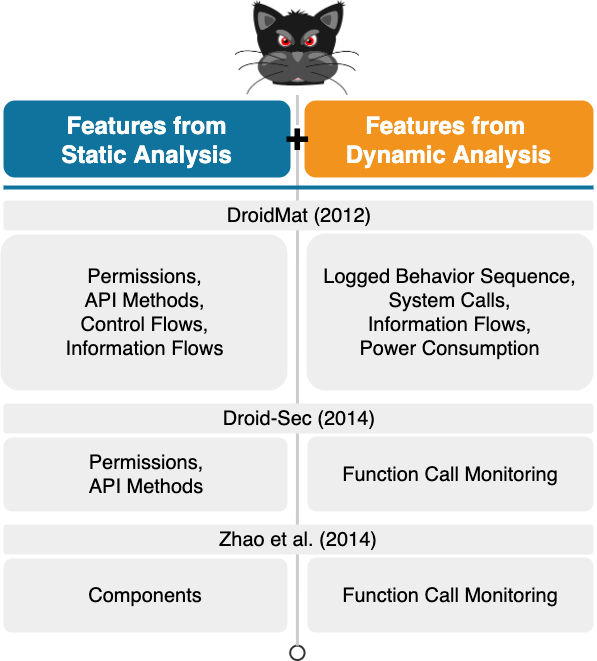
To overcome the issues of both static and dynamic analyses, other academic systems are proposed which train their models based on features obtained via hybrid analysis, i.e., a combination of static and dynamic analyses. Such systems are logically less vulnerable to trivial adversarial attacks. Examples of these kinds of ML-based Android malware detection systems are DroidMat, Droid-Sec and the system developed by Zhao et al. as shown in Fig. 9. DroidMat relies on permissions, API methods, control flows and information flows all obtained from static analysis, and, on the other hand, on the logged behavior sequence of applications, their system calls and power consumption, and, finally, their information flows from dynamic analysis to detect Android malware. Droid-Sec makes use of permissions and API methods obtained from static analysis, and function calls obtained from dynamic analysis to train its model. Finally, the system proposed by Zhao et al. is trained by function calls extracted during dynamic analysis from specific app components extracted during static analysis.
Many ML-based Android malware detection systems rely on one single supervised machine learning algorithm to distinguish malware samples from benign apps. Support Vector Machines (SVM) and k-Nearest Neighbors (k-NN) are two well-known algorithms frequently applied to such systems. The k-NN algorithm store all samples as feature vectors in a multidimensional feature space, each with a class label during the training phase. Then, a new sample is assigned with a label in the testing phase based on the labels of its neighbors (k constant, defined by user). Thus, k-NN algorithm is very easy to implement, it does not have any assumptions, nor does it need to build any models in the training phase. However, it cannot scale well as the training dataset grows, and, most importantly, it suffers from a phenomenon, called the curse of dimensionality. In other words, as the number of features increases or the feature space grows, the algorithm is left with a huge sparse matrix for its features which renders the classification task very difficult and challenging. On the contrary, the SVM learning algorithm constructs a hyperplane or set of hyperplanes in a high (or infinite) dimensional space, which can be used for classification. As a result, this algorithm is more effective than k-NN in high dimensional spaces. However, it is not good for large datasets and does not perform well in two circumstances. First, when the dataset is noisy, i.e., when labels have overlaps. Second, when the number of features for each data point exceeds the number of training data samples. To compensate these disadvantages, few works have relied on multiple learning algorithms or ensemble learning algorithms (see Fig. 10) such as decision trees.

Regardless of the type and number of features or number of learning algorithms used by any ML-based Android malware detection system, models are very critical components in model-based machine learning algorithms. Models are the main engines used later by such systems to discriminate between malware and benign applications. Thus, any attacks or manipulations to this model can make the detection system ineffective. Therefore, it is important to study the place where ML-based detection systems store their trained model. From this point of view (Fig. 11), few systems like Drebin and IntelliAV store their models on the device (or smartphone); other systems store the models out of the device on a remote server (e.g., DroidAPIMiner and LoopMC), and the rest of systems store their models on the cloud (e.g., ScanMe Mobile). Normally, on-device models are more prone to adversarial attacks although developers of such systems usually encrypt or obscure the details of their models. However, the classification task is performed much faster by systems which keep their models on the device. In contrast, cloud-based models are less prone to manipulations and are thus more secure. In addition, systems which make use of cloud-based models have a minor effect on the device's performance, including its battery consumption. However, the classification response time could be longer compared to systems with on-device models. Moreover, the device should be connected to the Internet to benefit from these kinds of systems.
Discussion and Conclusion
Many systems have been developed and released in recent years for both Android application triage and Android malware detection. Despite the improvement of these systems and the establishment of severe vetting processes on online markets, Android malware still finds its way to official and third-party online app stores as well as users' devices. During this blog post, I briefly discussed the list of most popular Android app triage systems and malware detection systems from both signature-based and ML-based types. In addition, I discussed possible anti-analysis methods that are applied to Android malware in order to evade such systems.
Three major goals must be fulfilled for any type of attack leveraging anti-analysis techniques to be considered as a realistic adversarial attack. First, the app's integrity must be maintained. Second, it's malicious behavior must be preserved, and, third, the app must be able to evade ML-based malware detection systems. Thus, changing the app's features to evade detection systems is not the ultimate goal of an attacker since the modified application must be installable on a wide range of mobile devices. This issue is sometimes neglected by some academic works that study adversarial attacks against Android malware detection systems.
On the other side and in response to evolving adversarial attacks, especially against ML-based systems, two major factors should be taken into account. First of all, features must be robust at least against simple manipulation (or data poisoning) attacks which are used frequently by Android malware. Second, ML-based systems must be trained using Adversarial Training. Speaking in other words, adversarial examples (i.e., Android apps with noisy features which result in an incorrect output in the ML-based detection system) must be used during the training phase of such systems to improve their robustness in general.